Data Lakehouse has been one of the go-to data platform architectures in the present day. They offer robust capabilities like ACID transactions, inserts, updates and deletes over massive piles of data, while also providing time travel, schema evolution and query optimization through metadata. Open table formats like Iceberg, Hudi and Delta have made it possible to get a lakehouse up and running quickly.
Limitations of existing frameworks
Although existing frameworks excel at what they do, they do have their own set of limitations. Some of them include,
- Lack of native ingestion capability
- Lack of native querying capability
- Lack of native materialized view support
- Lack of real-time capabilities
- Lack of indexing
- Lack of dynamic workload optimization (have to be manually configured for said data consumption patterns)
This is by no means a generalized set of limitations, instead highlights that no one framework does all of these, instead each framework has its own drawbacks.
LakeDB
LakeDB is a concept based on Google Napa. It lays down a vision for an intelligent, single, unified framework that addresses all these limitations and provides the user a flexibility to tune the system for data freshness, resource costs or query performance.
LakeDB includes all the three core components involved in building a data platform: ingestion, storage and querying. It intelligently optimizes querying, including by generating materialized views, delta files / storage compaction and controls ingestion rate to allow system resources to be utilized for higher priority tasks.
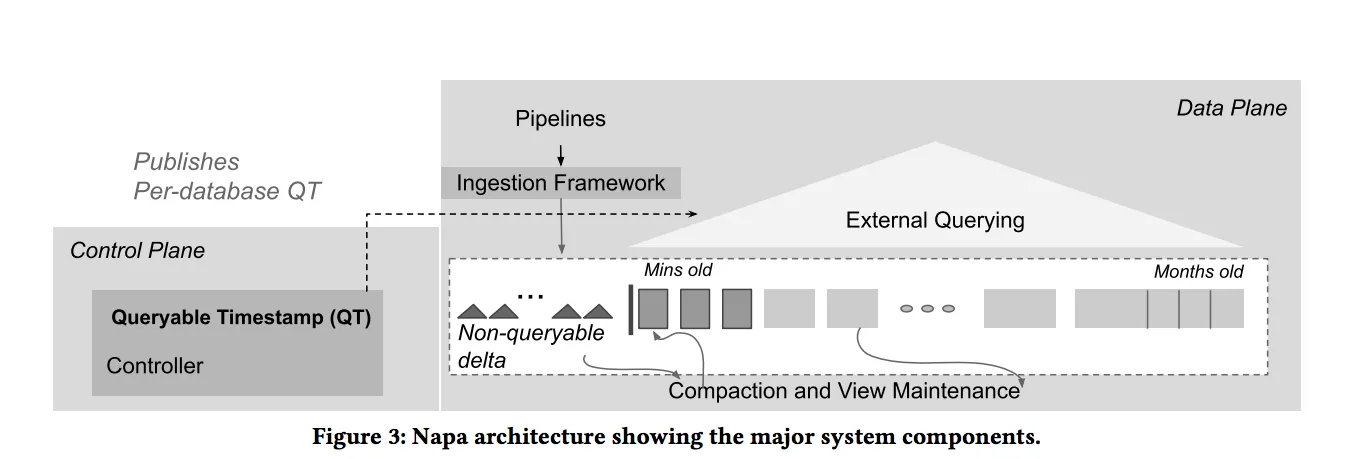
Queryable Timestamp
Querytable Timestamp (QT) is a way to balance data freshness and query performance at a table level. It allows to specify a time period, during which, newly ingested data is not queryable i.e., not part of the client query results. This gives time for the data from this time period to be optimized and be available for querying.
Data Governance
Unfortunately, data governance has not been focussed on in the research paper. It is a challenging topic none the less, in any data architectures. If someone does go along to build a LakeDB framework from scratch, I would love to see a data governance component, including access controls, baked right in, so that we don't need external systems to manage them.
LakeDB availability
Google Napa is the only known LakeDB system as of writing this blog along with some SaaS offerings like ChaosDB etc. A LakeDB solution can still be built by integrating a couple of open source frameworks already available today. But for a single, fully compliant open source LakeDB framework to come up, I see it as still an year or two into the future.
 I am Karthik, I love exploring data technologies and building scalable data platforms.
I am Karthik, I love exploring data technologies and building scalable data platforms.