Data deduplication is a process of eliminating repeated data, which helps in reduced network transfer and makes better utilization of storage. In the long term, it also helps reduce the size of data that needs to be processed to gain insights.
Repeated data is usually sent by IoT sensors, website telemetry and other systems, that are usually designed to send data at regular intervals and not when an event occurs (a state change).
In most cases, we do not need the repeated data and would only be interested in a state change event. If a state change happend at time t1 and and another at time t2, we can say that starting from t1, until t2 occured, the state was t1.
In this post, let us explore how we can use the in-built HDFS backed state store, in spark structured streaming, to deduplicate data in a stream and store only the state change events. This is an example of how you can do stateful processing in apache spark.
If you have not already, go through the spark structured streaming word count program, before proceeding ahead with below guide.
We will take example of a fitness band, that publishes users' body temperature, every second, to a server. We will push the data to kafka and use spark job as a consumer to read this data, batch into 5 second windows, perform deduplication and store it in parquet files. Temperature is our state variable here, i.e., temperature change is what we call the state change.
Since body temperature is not something which changes every second, we are bound to get repeated data and thus a need for deduplication.
Do note, although we batch the data into 5 second window, since we use the state store, the deduplication spans across the batches. To deduplicate data within a single batch, you do not need a state store.
Step 1: Define Data Schema
We create a case class to define our input structure. However, since we are only performing deduplication and no transformations, our output will also have the same schema.
case class UserData (user: String, temperature: Int, eventTime: Timestamp)Step 2: Deduplication logic
We can now define our deduplication logic. It is as below.
- Sort the batch based on event time [so that we can easily compare the current record with it's previous one]
- Use a current state variable to hold the previous state record initially and then the previous record in the same batch.
- Iterate over every record and filter it out if it's temperature is same as the previous one.
- Update the state store with the last seen state from the current batch.
implicit def ordered: Ordering[Timestamp] = (x: Timestamp, y: Timestamp) => x compareTo y
def deduplicate(user: String,
currentBatchData: Iterator[UserData],
state: GroupState[UserData]): Iterator[UserData] = {
var currentState: Option[UserData] = state.getOption
val sortedBatch = currentBatchData.toSeq.sortBy(_.eventTime)
val results = for {
userData <- sortedBatch
if currentState.isEmpty || currentState.get.temperature != userData.temperature
} yield {
currentState = Some(userData)
userData
}
state.update(currentState.get)
results.iterator
}Step 3: Read Data from Kafka
We will now read data by subscribing to the kafka topic, convert the bytes to json and select only the required columns.
val inputSchema: StructType = new StructType().add("ts", TimestampType).add("usr",StringType).add("tmp",IntegerType)
val df:DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers",kafkaBroker)
.option("subscribe",kafkaTopic)
.load()
val data: Dataset[UserData] = df
.select(col("value").cast("STRING"))
.select(from_json(col("value"), inputSchema).as("jsonConverted"))
.select(col("jsonConverted.usr").as("user"), col("jsonConverted.tmp").as("temperature"), col("jsonConverted.ts").as("eventTime"))
.as[UserData]Step 4: Data Deduplication using State Store
Now that we have our dataset, we can deduplicate our data. We do this by grouping the data by user id and then for each of the grouped record, we will call the deduplicate() method while using a flatMap.
val deduplicated: Dataset[UserData] = data
.groupByKey(_.user)
.flatMapGroupsWithState[UserData, UserData](OutputMode.Append(), GroupStateTimeout.NoTimeout)(StateOperations.deduplicate)See how we specify the input and output class for the generic method. You can choose to have a different output class. You can also use mapGroupsWithState() if you intend to return a single record from your stateful operation.
Step 5: Specify Checkpoint Location and Start Streaming Query
We can now start the streaming query. However, let us specify a checkpoint location, so that our state store is fault tolerant. We will also specify our output directory and our window duration using trigger.
val deduplicatedQuery: StreamingQuery = deduplicated
.writeStream
.format("parquet")
.option("path", deduplicatedOutputPath)
.trigger(Trigger.ProcessingTime(s"$windowSeconds seconds"))
.outputMode(OutputMode.Append())
.option("checkpointLocation", s"${deduplicatedOutputPath}_checkpoint")
.start()
deduplicatedQuery.awaitTermination()After running this job for a while, you can check the output at the specified output path.
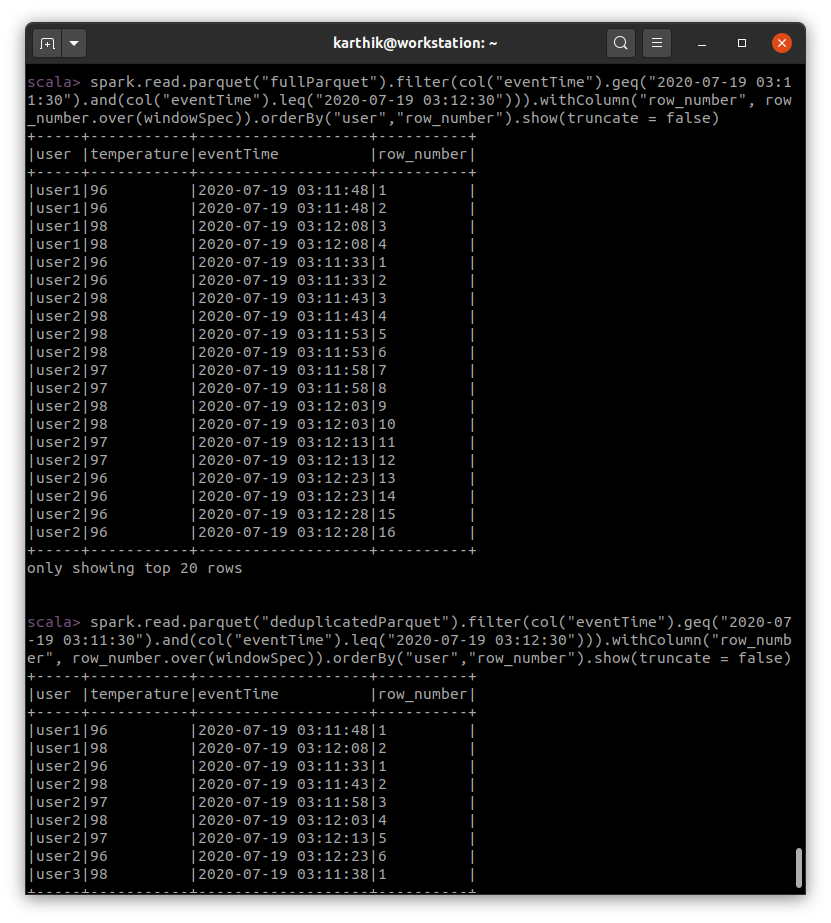
Below is the screenshot of results before deduplication and after deduplication.

Closing Notes
This job does not handle late data. You can put a simple check in deduplicate() method to allow data that has timestamp less than the current state timestamp.
With state store, we can also specify when the state expires/timesout. This will be useful when storing the state of user sessions like logins / payment transactions etc.
Spark has only HDFS backed state store for now, but you can specify custom state stores. RocksDB is a database that is popularly used as spark state store.
Do head over to the checkpoint directory and check how the state is stored on HDFS as delta files.
The full source code along with run instructions for this tutorial is available on git. You also have a data producer located at src/test/resources/dataProducer.sh.
 I am Karthik, I love exploring data technologies and building scalable data platforms.
I am Karthik, I love exploring data technologies and building scalable data platforms.