Word counts are the hello worlds of bigdata. In this post let us write a streaming word count program using spark structured streaming.
As seen in our spark essential guide, spark structured streaming is a streaming capability coming from SparkSQL component, not the spark streaming component.
This will be built on top of the batch word count program we already wrote for the spark core. So, head over to that post first, understand it and proceed with the below.
We will read the data from the kafka, by creating a topic in the kafka cluster we set up.
Step 1 and 2 remain the same, we clean the data and then tokenize it. We will not use the key-value approach in this tutorial. Instead, we will use the groupby() and count() functions to get our word frequencies.
Step 3: Add Spark SQL Kafka Connector
Kafka support is not built-in in SparkSQL, so we will need to add a dependency in our ./gradle/libs.versions.toml file.
spark-sql-kafka = { module = "org.apache.spark:spark-sql-kafka-0-10_2.13", version.ref = "apache-spark" }Step 4: Define Kafka Input Schema
Kafka sends the data as raw bytes. Since we read from Kafka, we need to define the schema to structure this data.
Our producer will send json messages to kafka in the format {"ts":<LONG>,"str":<STRING>}, where ts is timestamp in epoch seconds and str is a string containing multiple words (a sentence!).
Timestamp coming from the source is usually called an "event-timestamp", it is the timestamp at which the message was generated. We will not use the timestamp field in this tutorial.
Let's define the schema in our run() method of the Driver.
val inputSchema: StructType = new StructType().add("ts", TimestampType).add("str",StringType)Step 5: Subscribe to Kafka Topic
If you don't know what a kafka subscription is, go through the Kafka Essential Guide.
We first need to subscribe to the kafka topic, from which we want to read the data from. Let's subscribe and read the data into a dataframe.
val df: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers",kafkaBroker)
.option("subscribe",kafkaTopic)
.load()Step 6: Convert raw bytes to data
The dataframe df, being read from kafka, will now have the schema as shown below.
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)We are only interested in the value field. Note that the timestamp in the above schema is not the event-timestamp which we produce. It is the timestamp at which the message was received at kafka.
Let us cast the value field to string, parse the string as json using the schema we defined and select only the str field from the json.
val data: Dataset[String] = df
.select(col("value").cast("STRING"))
.select(from_json(col("value"), inputSchema).as("jsonConverted"))
.select("jsonConverted.str").as[String]In case if you are wondering what the data schema would look like after using the schema to generate jsonConverted field, here it is.
|-- jsonConverted: struct (nullable = true)
| |-- ts: timestamp (nullable = true)
| |-- str: string (nullable = true)Step 7: Word Count
Let's run our word count logic. Note how we use groupBy() and count() instead of key-value generation and reduceByKey() as in our batch word count post.
val words: Dataset[String] = data
.map(WordCount.cleanData)
.flatMap(WordCount.tokenize)
.filter(_.nonEmpty)
val wordFrequencies: DataFrame = words
.groupBy(col("value")).count()
.toDF("word", "frequency")Step 8: Start Spark Structured Streaming Query
Streaming query is how SparkSQL does streaming. It is an unbounded, continuous stream of data. Every streaming query can have only one sink. If you need to write data to multiple sinks, you will have to create streaming queries for all of them.
val query: StreamingQuery = wordFrequencies
.orderBy(desc("frequency"))
.writeStream
.format("console")
.outputMode(OutputMode.Complete())
.start()Our sink here is the "console", that's right, we just display the result on the console and not write it anywhere.
We use "complete" output mode, which does a running aggregate. Spark computes aggregate for every batch and discards the actual data, only persisting the aggregate state upto that batch (not the state of every batch). It combines this data with the next batch and thus keeps the state of running aggregates.
We call the start() method to start running the query.
Step 9: Wait for streaming query to complete
The start() method is non-blocking, so the application will immediately exit. To prevent that from happening, we will call a awaitTermination() method on the query. This is a blocking call and thus keeps the application alive till the query exists (forever, in our case).
query.awaitTermination()Step 10: Output and Event Timeline
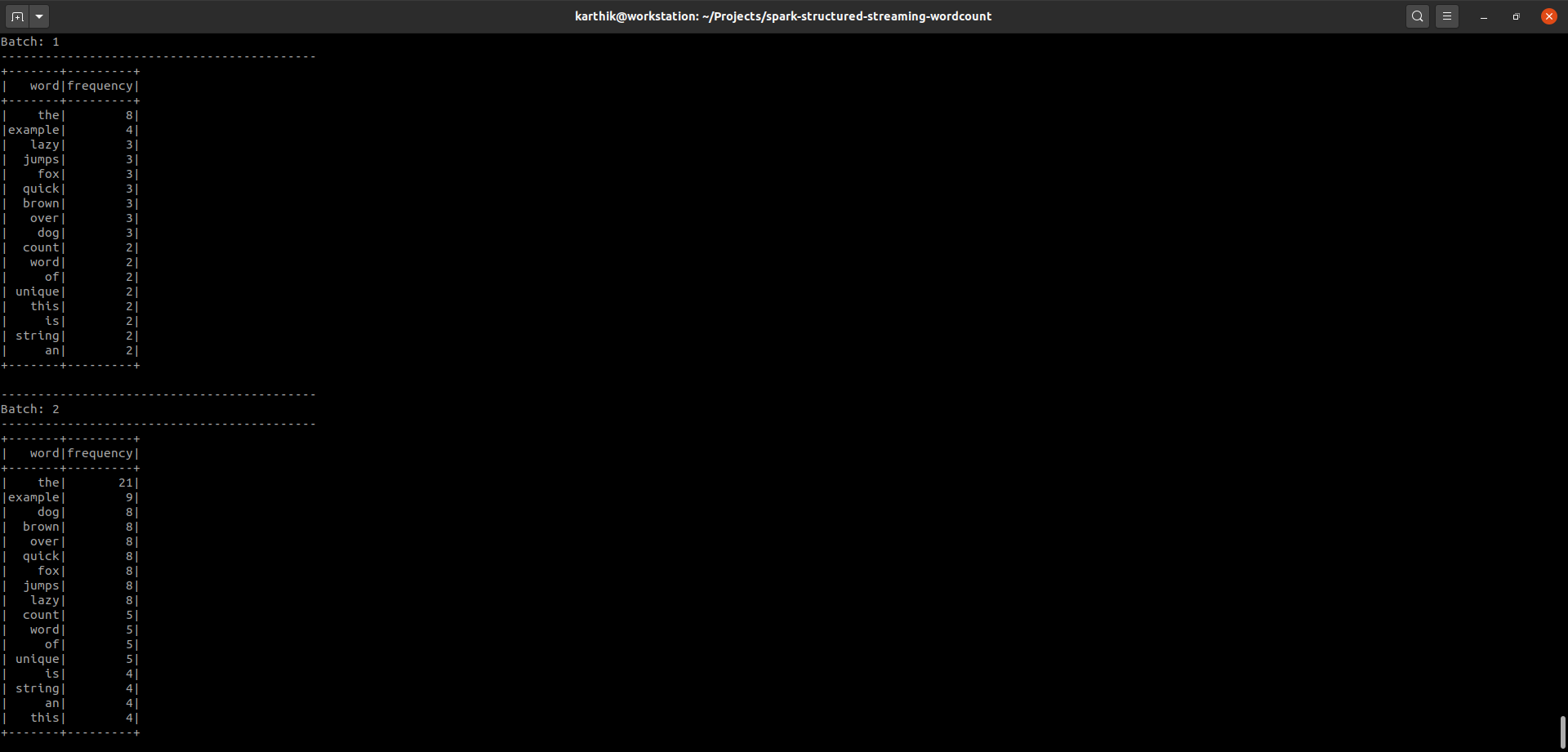
Once you run this job, you should start seeing the running aggregate on your console as shown below.
The event timeline on the Spark UI will look like this.

Note that I used the producer from the project, which publishes a message every second to kafka.
I was using a very low end vm and kafka was also running on the same vm. So, every batch was taking about 15 seconds to process.
Head over to git for the full project.
 I am Karthik, I love exploring data technologies and building scalable data platforms.
I am Karthik, I love exploring data technologies and building scalable data platforms.